読書:『意識はどこから生まれてくるのか』(マーク・ソームズ)
意識に関する書籍は、ジュリオ・トノーニの『意識はいつ生まれるのか』以来、とても久しぶり読んだ。
本書マーク・ソームズの『意識はどこから生まれてくるのか』は、概して大変興味深く、いくつかの点で自分が漠然と持っていた意識と脳に対する認識は大幅に変わった。
特に本書前半の議論(第1~6章)、意識は認識的というよりも感情的(あるいは「感じ」)で、脳における意識の座は大脳皮質ではなく、脳幹上部であるという主張は、実際に脳に障害を受けた人の症例を多く扱い、個人的には説得力があった。
また、心理学における行動主義以降、徹底して軽んじられていた内観報告の役割を重視した神経心理学研究、著者が神経精神分析学と呼ぶもの、も新鮮で面白かった。
フロイトが元々しっかりとした神経生理学者で、当時の神経生理学的な技術的限界から精神分析学を興したことはどこかで読んで知っていたが、将来的な技術発展を見据えたプロジェクトまで構想していたことは、本書を読むまで知らなかった。
著者はフロイトが当時挫折せざるを得なかった、このプロジェクトを現代に蘇らせたらしいので、時間があったら少し読んでみたい。
しかしながら、自由エネルギー原理が出てくるあたり(第7章)は個人的には微妙だった。
すでに一冊自由エネルギー原理に関する本は読んだことがあるが、やはりなんというかFEPは腑に落ちない。
本書にの説明においても、結局のところ予測誤差を最小化する(FEP的には自由エネルギーを最小化する)ことが生命にとって重要で原理であると、端的に言えば述べているだけで、そこまで劇的なものとは思えない(ホメオスタシス的なネガティブフィードバックシステムに関しても、雰囲気、制御工学的システムを情報理論の観点から捉えなおして、適応範囲を広げた以上のことではない気がしている)。
情報系の自分には、物理学関連の用語と概念が多用されているのでハードルは高いが、そのうちFEPに関してはちゃんと時間をとって学ぶ必要があるかもしれない…
また、フリストンが構築したらしい自己組織化システムと、そこでの重要概念と捉えられているマルコフブランケットあたりの議論は、正直オートポイエーシスや人工生命分野で散々やられてきたことの焼き直しなのではないかという気がするし、神経系が実現する自己組織系と、単細胞レベルで実現される自己組織化系ではギャップが大きすぎて、著者の主張にそこまで乗れなかった。差分として敷衍されている自己組織系の内部における外部のFEP的な予測の話が、なにかこれまでにない凄いことなのかもしれないが、これも判断がつかなかった。
第11章の「意識のハードプロブレム」は期待していたが、チャーマーズの元々の論文を縦軸に議論する形で、恐らくあと1~2回読み直しても理解度は7割を超えない気がしている。大枠雰囲気で理解した範囲では、チャーマーズのハードプロブレムの議論には、概念の混合があり、根本的にハードプロブレムではないという話に帰着しようとしているように見受けられるが、正直この辺りはチャーマーズの原論文と適当な副読本を含め、しっかり読まないとついていけないと感じた。
第12章の「心を作る」では、本書での知見を用いて実際に意識を持った機械を作る具体的な方法について論じているが、その試みの構想は大変ナイーブに感じた。実際に人工生命研究とかを行った経験のある人なら多かれ少なかれ理解されると思うが、これこれこういうステップで目的の生命的な振る舞いや認知をシミュレートするという研究は、試行錯誤の連続で、ほとんど最初の構想通りにはいかない(個人的経験)。
とはいえ、本書通してこの著者は、1つならず、多くの大胆な発想や主張を行ってきており、何か面白い結果が得られる可能性は期待している。
経験分布の収束について
概要
ブートストラップ法を勉強していて,経験分布に関して興味が湧いた点があったので個人的に整理する.
具体的には,経験分布関数が元の分布関数へ大数の法則より収束することと,類似に定義できる経験密度関数がヒストグラムと対応でき,こちらも概ね(?)元の分布の密度関数へ収束することを示したい(願望).
この記事において,経験分布関数の定義との扱いあたりは、概ねこの本の1章に基づく.
経験分布の定義と各種グラフ
簡単のため,以下で扱う分布関数は微分可能であり,密度関数
が存在すると仮定する.
まず,IIDで分布関数に従うN個の確率変数を
,その実現値を
とする.
ここでに関する経験分布関数
は次のように定義される.
ただし,,
は次のように定義される
である.
次に例示として,標準正規分布における分布関数と,の標本に基づく経験分布関数のグラフを示す.
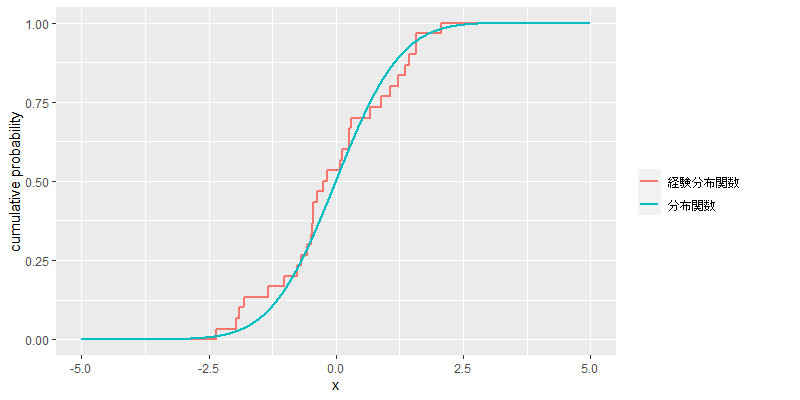
ある区間サイズについて,経験密度関数を次のように定義する.
ただし,,
とする.ここで
は床関数である.
(注:ここでの経験密度関数は,ヒストグラムと密度関数の対応を見るために導入したこの記事独自のものである)
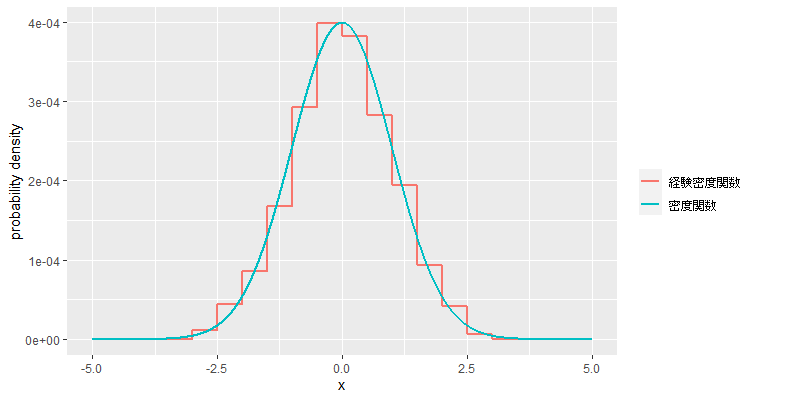
次に例示として,標準正規分布おける密度関数と,の標本に基づく経験密度関数のグラフを示す(
).
AICの背景からのAICcの導出
このブログでは,下記記事のAICの導出における背景を踏襲してAICcの導出を行う.
主要参考文献は下記の3つである.
AICの背景に追加の前提
AICの導出では,モデルの取る分布はパラメトリックなクラスに属するという仮定しか置いていなかったが,AICcの導出においては,モデルの取る具体的な構造を正規線形モデルに限定する.
ここでは
の計画行列,
は
次元のパラメタベクタ,
は
の単位行列である.
このモデル設定において,真のモデルは平均を,分散共分散行列を
とする
次元の多変量正規分布である;ここで
の列数と
の次元は未知であることに留意する.
尤度関数は具体的に次のように定まる.
とおき,このモデルにおける最尤推定量
は次のように求まる.
個の観測に関するカルバック不一致は次のような形になる.
は次に示すように
倍した
個の観測に関するカルバック不一致
と等価であることに留意する.
ここでである.
AICcの導出
追加された前提も含め,個の観測に関する期待カルバック不一致を求める.
まず,であり(Puntanen et al. (2013)),
の定義から
であることから,
は
に従い,
は
に従う(Hamada et al. 2008).このことから
の第2項は次のように求まる.
次に,候補モデルのクラスに真の分布
が含まれているという強い仮定を置く.この仮定の下では,
かつ,
は未知の
次元パラメタベクタである;仮定により
の第3項は次のように変形できる.
正規線形モデルにおいて,最尤推定量である回帰係数は誤差の線形変換と等価であり,
は多変量正規分布
に従うことから(Madisen and Thyregod (2010), p.49, Theorem 3.3),
の第3項の期待値内は次のように
分布に帰着できる.
ゆえに
最終的に全体としてまとめるとは次のようになる.
ここでは
倍した最大対数尤度であることに留意する.
ここからAICcは次のように定義される.
AICcの期待値はとなる.
等価なものとして,AICcはしばしばを用いても示される.
赤池情報量規準の導出
Cavanaugh and Neath (2018)を読んで得た理解のまとめ.
以下の導出の最終的な主張は文献よりも弱く見えるが,これは自分が理解している範囲で正しい結果に留めた結果である.
背景
未知である真の分布から独立に生成された
個の観測値
を特徴づける適切なモデルを選択する状況を考える;ここで観測値は独立であるから,同時確率
である.
観測値を定式化あるいは説明するモデルを候補モデルと呼ぶ.任意の候補モデルは構造的に確率分布のパラメトリックなクラスに対応し,具体的には,ある候補モデルは
次元パラメータベクタを取る密度関数のクラス
によって表される.
ここでは
次元ベクタで構成されるパラメタ空間である.文献中,
次元ベクタの要素は
であると書かれているがなんの事はわからない
は密度関数
に対応する尤度関数を表す:
である.
はパラメタ空間
上で尤度
を最大化して得られる推定量のベクタを表す.
多様な構造と次元を持った候補モデルの集まりを考える;最終的な目的としては,この候補モデルの集まりの中から,真の分布
の最も良い近似となるモデルを探すことである.ここでの最も良い近似となるモデルは,理想的には
の顕著な特徴を捉えつつ,また得られたデータだけでは正確に推定することができないノイズ等の不要な特徴を無視する.
真の分布と候補モデルの乖離の程度を測定し,これを最小化するモデルとしてより良い近似を得ることを考える;この目的のためカルバックライブラ情報量を用いる.に関する
と
間のカルバックライブラ情報量は次のように定義される.
は厳密には距離関数ではないが,
と
が異なっていれば異なっているほど増加し,その逆も成り立つので,これら密度関数の乖離の程度を測定するのに使用できる.
次にの
に着目して次を定義する.
の
は定数なので,
に基づいて行った候補モデルのランク付けは,
に基づいたランク付けと等価である.ゆえに
は
の適切な代替として利用できる.
をここではカルバック不一致と呼称する.
重要な点として,カルバック不一致は未知である真の分布に依存しているため,実際には
を求めることはできない.
モデル選択のための妥当な規準を得るため,の期待値を考え,そしてパラメータとしては最尤推定量
を使用する.
はしばしば期待カルバック不一致と呼ばれ,カルバック不一致
と同様に,
も実際には求めることはできない.
導出
赤池情報量規準はの近似として導出され得る.
次のようにが大きくなるとき,大数の弱法則から,
倍した平均最大対数尤度はカルバック不一致の一致推定量である.
このことからは
の自然な推定量である.
最終的に個の観測おける最大対数尤度
を使用した近似を行うため,ここからは
倍した期待カルバック不一致
を近似することを考える.
以降の記述では簡潔さのため,の下付き文字を省略する.
まず,真の分布がパラメトリックなクラス
に含まれているという強い仮定を置く.この仮定の下で,真のパラメータを
とすると,
は
という形式で表現できる.また,最尤推定量
の漸近正規性と一致性を保証する正則条件も満たされているものと仮定する.
次にの等価な次の変形を考える.
ここでである.
また上の式のは次のように
となることに留意する.この関係は後で使用する.余談だがこの関係は定数と考えられる
の代わりに確率変数である
を使用した場合には当然成り立たない(自戒)
ここからと
を求める.
に関して,
を近似的に求めるために,
を
まわりで2次までのテイラ展開を行い,その結果の期待値を取る手順を踏む.
対数尤度の微分は最尤推定量の点で0になるため1次の項は無視できる.
Divergence: from 0.571024% to 1.130209%
ここではObserved Fisher情報量である.
Observed/Expected Fisher情報量の違いや性質,また関連する漸近正規性の導出等はPawitan (2013)が詳しくわかり易い
期待値を取って次のようになる.
上の式をの
に代入し,
自体は次のようになる.
ここでは漸近的に多変量正規分布
に従い(Madisen and Thyregod (2010), p.22, (2.38)),
の期待値内は
分布に従う;ゆえに
は次のようになる.
次にに関しても,
と類似し,
を近似的に求めるために,
を
まわりで2次までのテイラ展開を行い,その結果に
を乗じて期待値を取るという手順を踏む.
次のように1次の項は0になる(微分と積分の順序交換は無邪気にできると仮定する).
したがっては次のようになる.
ここでは1個の観測に関するExpected Fisher情報量である.
期待値を取って次のようになる.ここで二重の期待値の外側がに関するものであったことに注意すると
である.
ここでは
個の観測に関するExpected Fisher情報量である.Expected Fisher情報量の性質として
である.
上の式をの
に代入し,
であったことに注意すると,
自体は次のようになる.
の場合においても,
は漸近的に多変量正規分布
に従い(Madisen and Thyregod (2010), p.22, (2.37)),
の期待値内は
分布に従う.ゆえに
は次のようになる.
と
に関して得られた結果をまとめると漸近的に次のようになる.
ここから最終的に赤池情報量規準は次のように定義される.
の期待値は漸近的に
倍した期待カルバック不一致を近似する.
Divergence: from 1.130209% to 0.571024%
上から分岐.以下の議論は自信がない.単なる怪聞になっているかも知れない.
対数尤度の微分は最尤推定量の点で0になるため1次の項は無視できる.
また,最尤推定量の仮定された一致性から
このことを確率的ランダウの記号を用いて表示すればとなる.最尤推定量は確率変数なので通常の極限的に
のような近似誤差の評価できないと考えられる;この点を考慮して最尤推定量の一致性を利用するなら
になるはずである.
上述のように確率収束する近似誤差を考慮に入れて展開を進め,追加で一様可積分性のような正則条件が満たされていると仮定するととなり(こことここを参照;なにか公式なソースではないので確証はないが...),最終的に期待カルバック不一致は次のようになる.
ここから赤池情報量規準は次のように定義される.
ここでの期待値は
で
になる誤差を伴って
を近似する.
所感
本編導出では,Cavanaugh and Neath (2018)に頻出する記号であるが,ベクタ(複数の観測)なのかスカラ(1つの観測)なのか,確率変数なのか実現値なのか,どこまでの文脈の範囲で同じで,また違うのか正直良くわからなかったため,全体の方向性は踏襲しつつも,カルバックライブラ情報量の期待値における変数は1変量の確率変数にすることを主軸とし,直感に適うことを優先しながら曖昧な点を順次確定する形で導出を行った.
Cavanaugh and Neath (2018)と最終的な形は異なるが,少なくともを一貫してベクタとして捉えると等価になる気がする(ぱっとした想像だけで厳密に検証はしてないが;ただしこの場合カルバックライブラ情報量の期待値の変数もベクタになり,個人的に解釈が難しい);一貫してスカラの場合,多分難しそうなのと,今の自分の知識の範囲ではObserved Fisher情報量とExpected Fisher情報量あたりで突っかかりそうな気がする.
またCavanaugh and Neath (2018)の導出ではテイラ展開の誤差の評価としてが現れている.調べてみたものの自信がないので,本編導出では全て近似で乗り切ったところであるが(Divergence: 0.571024%),一応
が現れる道筋はつかめている(Divergence: 1.130209%).この点については厳密に確証を得ようと考えると中々難易度が高そうである;測度論的確率論がわからないので,その基礎からはじめて半年~1年程度は要しそうである.まったくもって自明で無いように見えるのに,なぜCavanaugh and Neath (2018)には別段の説明もなく,さらっと
が登場しているのかは本当に疑問である.ただ自分が遠回りしているだけで,なにか簡潔に進める未知の前提がどこかにあるのかも知れない.んーとても口惜しい.途中の世界線変動率には特に意味はない.ラ・ヨダソウ・スティアーナ
ベイズ情報量規準と修正付き赤池情報量規準を経由して,ようやく赤池情報量規準の導出を一通り追ったが,漸近正規性関連+ExpectedとObserved Fisher情報量まわりでも大変混乱した.これらはいくつかの点で,証明なしにテキストに載っていることをそのまま信じる形で導出を進めたが,いまだ拭えない不安が残っている.現状時間が足りないが,いつかこれらもしっかり基礎から学習して不安を払拭したい.手近でHeld and Bové (2014)にこの辺りがざっくり載ってることに気がついた.まぁ近いうちに
の導出途中で狐につままれたような
と等価な変形を行ったが,Konishi and Kitagawa (2008)のFig. 3.7で図示されるような期待対数尤度と対数尤度間で生じるバイアスの分解と類似のものな気がする.ちゃんと対応をとって見てないのではっきりとは言えないが.
Konishi and Kitagawa (2008)と言えば,この本に載っているAICcの導出は,明確にテイラ展開や漸近正規性を用いないと書かれているサブセクション(3.5.1)に基づいているが,式(7.65)から(7.66)の変形では暗に最尤推定量の漸近正規性を利用しているように見える.あるいは Madisen and Thyregod (2010)のTheorem 3.3に記載されてるように一般線形モデル(正規線形モデル)においては,誤差に仮定された正規性から直接的に回帰係数の推定量が正規分布に従うことが求められるので,ここでの疑問点は解消した.を漸近正規性を用いずに求める方法があるのだろうか?今の自分にはわからない
今回も例にもれず,改善点・間違い等は見つかり次第修正する.
修正済み赤池情報量規準(AICc)の導出
Hurvich and Tsai (1989)を流し読みして得た理解まとめ
準備
まず,データは次のTrue Modelから生成されたと仮定する.
Hurvich and Tsai (1989)ではTrue Modelの意味でOperating Modelという用語が使われているが,どういうニュアンスを含んでいるのかよくわからない
また,近似に用いるモデル族として次のものを考える.
は
次元ベクタ,
は連続で2階微分可能であると仮定する.
近似に用いるモデルとTrue Modelの具体例として,両者が線形モデルであるとすると,,
となる.ここで
と
は各々に
と
のフルランクの行列,
は
次元ベクタである.
近似に用いるモデルとTrue Modelの乖離を測る有用な指標として,カルバック・ライブラ情報量がある.
ここでは期待値がTrue Modelに関するものであることを示し,
は近似に用いるモデルに基づいた尤度関数である.ここでのカルバック・ライブラ情報量は定数になる項を無視し,
をかけている.
カルバック・ライブラ情報量が小さいほど,対象となったモデルとTrue Modelの乖離が少ない.
正規分布についての尤度関数を次に示す.
具体的に得られた尤度関数からカルバック・ライブラ情報量は次のようになる.
補足蛇足
妥当な規準として近似に用いるモデルを評価するため,カルバック・ライブラ情報量の期待値を取り,パラメータとして得られたデータに基づいた最尤推定量
を使用する.
最尤推定量を適用してカルバック・ライブラ情報量は次のようになる.
Hurvich and Tsai (1989)では,この段階でが定数として無視されるが理由は不明.
を無視すると尤度との関係がわかり難くなるので良いことはない気がするが…
近似に用いるモデル族が複数あるとき,を最小化するものが,ある意味でTrue Modelに最も近いものとして選択され得る.
実際にはTrue Modelは未知であるから,それに基づくも同様に未知である.しかし,何らかの追加の仮定が置かれることで,この量は推定され得る.推定され得る1例として,次に示す赤池情報量規準は近似的に
の不偏推定量を提供する.
ここでは近似に用いるモデルのパラメータの次数である.また,
は最大対数尤度
と等しい.
AICcの導出
ここでの目標は次のの推定量を得ることであり,それが最終的にAICcを導く.
まず,を定理として受け入れ,
の定義より
であることから,
は
に従い,
は
に従う.ここで証明なしに
を定理として受け入れたが,これは調べればWikiにも出てくる;自由度あたりが浅学過ぎて証明はわからない.書籍として少なくともPuntanen et al. (2013)には載ってる.
このことからの右辺第2項は次のように求まる.
以下,近似に用いるモデル族にTrue Modelが含まれているという強い仮定を置く.この仮定の下でTrue Modelの平均応答は
となる.ここで
は
次元の未知のベクタである.
次に,の
におけるテイラ展開による1次近似を考える.
ここでは
における
である.追加の仮定として線形モデルを考えると
は計画行列になり,
は多変量正規分布
に従う(Madisen and Thyregod (2010), p.49, Theorem 3.3).Hurvich and Tsai (1989)では
を線形モデルに限定した書き方はしていないが,非線形モデルの場合でも同様の正規性が導入できるのかは浅学過ぎてよくわからない.
以上からの右辺第3項の期待値内は近似的に
分布に帰着できる.
ゆえに
最終的に全体としてまとめるとは次のようになる.
そしてここからAICcは次のように定義される.
AICcの期待値はを近似する.
上のAICcの罰則項は少し見慣れないかもしれないが,正規線形モデル等で推定される分散もはじめから考慮に入れたパラメータ数としてとすれば,比較的よく見かけるAICcになる.
前のBlogでAICcの利用法に関して,情報量規準で意図される罰則項という観点から述べたが,AICcの導出過程から罰則項の分母は
今回も思いの外長くなった.Hurvich and Tsai (1989)を読んでざっくりは理解できた気がしていたが,これを書いてて理解の穴が多分にあることに気がついた.さらなる研鑽が必要である(小並感).なにか改善点・間違いに気がついたら修正する.
ベイズ情報量規準の導出のスケッチ
下記の文献のBICのところを流し読みして得た理解まとめ
link.springer.com
事後確率に基づくモデル選択
を
個の候補モデルとし,各モデル
は確率分布
と
次元パラメータベクタ
を取る事前分布
に特徴づけられるものとする.
ここでのモデルとは,回帰モデルにおいて説明変数を何個含むか,あるいはどのような分布が仮定されるかというような構造レベルのものである.
個の標本
があるとき,
番目のモデル
に関して周辺分布あるいは
の確率は次のように与えられる.
は
番目のモデル
の尤度と考えられる.また
は,このモデルで具体的なパラメータ推定をベイズ的に行う際の周辺尤度になっている.
を
番目のモデルの事前確率とすると,ベイズの定理に基づき,
番目のモデルの事後確率は次のように与えられる.
この事後確率は,データが観察されたとき,
番目のモデルからそのデータが生成された確率を表しており,
個の候補モデルから1つのモデルを選択する状況では,この事後確率が最も大きいモデルを採用するが自然と考えられる.
において,分母は全てのモデルで同一なので分子
のみを比較すれば良い;加えて事前確率
が全てのモデルで同一と仮定すれば,モデルの尤度
のみの比較で事後確率の観点から最良のモデルが選択できる.
ベイズ情報量規準の導出
事後確率に基づく先に説明した方針のモデル選択を実現するために,
の近似としてベイズ情報量規準は導出される.具体的な形は次のようになる.
が付いたので,この量の小さいモデルが事後確率の大きいモデルに対応する.
以下の導出過程は上の書籍のものとは異る.間違いが含まれているかも
の近似は,
が十分に大きいときに成り立つラプラス近似によって得られる.ラプラス近似は次のようなものである(今回はスケッチなのでラプラス近似は所与のものとして受け入れる).
ここでは
次元パラメタベクタ
を取る実数値関数,
は
の最頻値である.
まず,ラプラス近似が適用できるようにを変形する.
ここではとした.
そして次の近似を得る.
事前分布が無情報事前分布であると仮定すると,
の
に関する大小関係は対数尤度
に一致する.ゆえに,ここで
は最尤推定量である.
が無情報事前分布であるという仮定は上の書籍にはないが,式(9.17)の近似で
のテイラ展開の第2項以降を無視するところから暗に想定されている気がする
両辺の対数を取ってをかける.
標本サイズに関して
以下の小さいオーダの項を無視して,最終的にベイズ情報量規準を得る.
標本サイズに関して
以下の小さいオーダの項を無視する部分は,直感的に
のとき,
のない項は無視できるくらい小さくなるということだと思うが,オーダの個人的な理解が足りてない
AICの導出に比べたら全然長くなさそうだから書き始めたが,思いほか長くなった.疲れた.途中ラプラス近似の適用の部分に不安があったが,確認したところ形式的には問題はなさそう.他になにか間違いがあったら,わかり次第修正する.
標本数とパラメータ数が近いときのAICcの挙動
検証用のシミュレーションを書いたり,調べ物をしてて,について気がついたことあったのでメモ.
 とは
とは
とは,モデル選択に用いられる情報量規準の1つであり,標本数
が漸近的に無限に大きくなることを仮定した
を,有限の
に修正したものである.
ここでは対象となるモデルの最大対数尤度,
はパラメータ数である.
直感的にが小さいとき(ただし
),
には
よりも強い罰則が加わり,
が大きくなるに従って
に近づく.
 のときの
のときの
標本数とパラメータ数
が同じとき,
の罰則項は負になり,むしろ報酬項になり得る.
この性質から,でモデル選択をする場合で,候補モデル中の最大パラメータ数
と標本数
が同じとき,その最大パラメータ数の候補モデル
は最も当てはまりが良く,加えて
に関してのみ罰則項が報酬項になるため,必ずその
が選択される.
より広くのとき,
の罰則項は報酬項になっているが,例えば線形回帰モデルであれば,
の計画行列
では
が求まらなそうなのであんまり意味はなさそう(線形代数力が足りなくて一般に証明は思いつかないが,
のとき,
は正則ではないと思う).
 のときの
のときの
標本数がパラメータ数
と同じとき,
はゼロ除算になるため,基本的に定義できない.
R言語など,ゼロ除算がと定義されている言語で
を実装してモデル選択をする場合,例外でプログラムが止まることはないが,
となる候補モデル中の最大パラメータ数のモデルは
が無限になるため,決して選ばれなくなる.
の使用について
一般に情報量規準が罰則項で意図しているモデル選択上のparsimonyは,において
で成り立たない(実装によっては最悪例外が飛ぶ).なので
は
での使用が推奨されると思う.
 でを使用した実例
でを使用した実例
先に説明したにおける
の挙動は式を見ればすぐ気がつくことができるものである.だが上の論文ではプロットのみから挙動を論じたため,この点について解釈間違いをしているようである.結論とは関わりのない些細な部分ではあるので大筋に影響はないが.